
人工知能が変える仕事の未来
著者:野村 直之
| 内容紹介 ■人工知能(AI)の活用によって、ホワイトカラーの仕事、企業の経営、多様な産業はどう変わっていくのか? 30年以上にわたり、人工知能(AI)の研究に携わり、現在も日々、AI関連の研究・技術開発を続け、昨今、内外のAI事情に通じた著者、通称「ドクター・ノムラン」が、AIの実態、AIにできること、産業、ビジネス、仕事へのインパクトを、最新の知見に「温故知新」の視点を加えつつ、掘り下げて展望します。 ■現在のAIブームを支えるディープラーニングの本質をわかりやすく伝えるとともに、知的生産プロセス、IoT、医療・ヘルスケア、監視機能が重要となる様々なサービス、製造業、広告、マーケティング、農林水産業、そして人事、人材マッチングに至るまで、AIをどう活かすことができるのか解説します。 ■本書では、著者が研究者の視点、産業応用を目指す技術者の視点に立ち、責任をもって考え抜き、経済社会、法律についても考察を加え、全体に一貫性をもたせるように腐心。シンギュラリティ論に代表される、AIに関する誤った未来予測、悲観論、過剰な期待論を退け、産業・ビジネスから教育、法制度に至るまで、日本が欧米中国に伍して取り組むべきAI開発の課題も展望します。また、一人ひとりがAIに負けない能力を身につけるために何が必要か、明らかにします。 ■ディープラーニングがどのようなものか、具体的に、直感的に理解していただくために、カラー図版による解説パートを収録しています。 |
★読書前のaffirmation!
[きっかけ・経緯] 人工知能ブームを煽る書物が多い中、これはそうではなく本質を突いたものだと期待して手に取りました。
[目的・質問] 人工知能ブームの本質を汲み取ります。
[分類] 007:情報科学
「はじめに」で、この本は信頼できると思いました。
| AI研究者や関連業界の様々な思惑から、過剰な期待を煽る言説が唱えられていることに関するものです。筆者としては、こうした過剰な期待感、あるいはその裏返しとしてのAI脅威論が、今後のAI開発にとって差し障りになることをに強い危機感を覚えます。(p.12) |
野村さん自身が、第一線のAI研究者。その彼がそう言っているということが非常に興味深いところです。
| 筆者の考えるところでは、今世紀中にはシンギュラリティが到来することはないでしょう。AIが模倣すべき知能を自然科学の対象として定義できておらず、知能はおろか新アイディアを発案するのに必要な素材としての知識の量、われわれ人間が脳内にもつ日常世界や社会についての「常識」の量や特性を工学的に計測することもできていないのが現状です。ましてや意識、自我、責任感を備え、情動に基づく行動、発言、自問自答から新しい仮説を自ら発想する機械を作るための理論が出来上がり、目途が立っているとは寡聞にして聞いたことがありません。(p.13) |
AIの定義自体、人それぞれ。確かに色々な分野に搭載されて成果が出始めているのも事実ですが、少し夢を見ているところは否めません。
| AIが属するソフトウェア技術というものは、これまで指数関数的には進化していません。開発ツールの進化や、オープンソースの共有によって2次関数的に進化が加速することはあっても、テレパシーをもたない人々の頭脳群の間で核分裂の連鎖反応のように指数関数的に思想、ひとつの思考の産物が肥大することはないのです。(p.13) |
私もユーザーとしてですが、この世界に多少なりとも関わっていますが、実際のところは、筆者のおっしゃる通りの状況だと思います。
| 現在、人間のように感じたり考えたり、また、人間に教えられなくとも勝手にどんどん学習したり、自らを進化させていくような真正の人工知能はまだ存在していません。とはいえ、脳の神経回路網を単純化して模した、ニューラルネットという半世紀の歴史がある技術(従来入力層、中間層、出力層の3層だったのを多層化したものを「ディープラーニング」と最近は呼びます)により、2012年にグーグルが猫の概念を獲得できたとするブレークスルーがあったり、2010年代になって急速に人工知能研究が進み始めています。(p.34) |
このあたりについては、大いなる誤解があるように思います。グーグルのアルファ碁などの報道を見ていると、機械が自分で「一手」を考え出しているかのように映ります。普通に見てると誤解してしまうと思います。
| ディープラーニング以外の機械学習最適化のアルゴリズムを含め、人工知能的なコンピュータ・ソフトウェアが実用的になってきた背景には大きな要因が2つあります。(pp.34-35) 1)大量データ(ビッグデータ)が発生、流通し、手軽に使えるようになった 2)計算機のパワーが前回の人工知能ブーム時の何千倍、何万倍にもなった |
これは本当に大きなトピックです。結局は、まさに多くのデータを使って、大量の計算が可能となり、ディープに学習ができるようになったということです。
| 人工知能(AI)には多彩な種類があります。技術的な分類以前に、まず、そもそも、対象データが従来はもっぱら人間が扱うしかなかったという意味でAI的なのか(画像や文章など)、情報加工のやり方、タスクの性質がAI的なのか(「学習」「予測」や「意味の理解」、曖昧な指示を解釈して作業など)、そして、技術がAI的(以前のブームの際の推論マシンやProlog、LISPなどのAI言語、探索・最適化アルゴリズムなど)なのかという違いを意識する必要があります。(p.42) |
さらっと難しいことが書かれていますが、理解できますでしょうか?ものすごく極論するならば、数値で解決しにくいものを(今のところは局所的ですが)解決できるようになったのが人工知能(AI)ということになります。
| 少し幅広く「知的なふるまいをするソフトウェア」と緩く定義しておいて、どんな種類の人工知能があるのかを考えてみたいと思います。3つの軸で分類します。ひとつめの軸は、「強いAI」vs「弱いAI」です。「強いAI」とは、「人間の脳と同じ振る舞い、原理の知能を作る」ことを目指すAI研究のことを指します。「弱いAI」は、「人間の能力を補佐 ・拡大する仕組みを作る」ことを目指すので、必ずしも人間の脳の構造や、機能さえも解明する必要はないということになります。2つ目の軸は、「専用AI」vs「汎用AI」です。汎用、専用というのは、互いに相対的な定義とすることもできます。・・・AI研究の世界ではもっと次元の違う汎用性、たとえば知識を新たに自分でその場で獲得しながら使いこなしていけるという、知識獲得・知識創造のための知識、すなわちメタ知識が期待されてきました。このメタ知識をもって、未知の事態にも、ある程度対応できるAI、汎用の学習能力をもったAIのことを汎用のAIと呼ぶことが多いようです。・・・3つめの軸には、知識やデータを膨大に活用しているか、データが大量でなければ(うまく)動かないか、あるいは、知識やデータが少量であってもそれなりに確実に役立つか、という対比を置きました。知識やデータの多いか少ないかの違いは、知識量は少なくとも賢い、高精度に対象を識別したり適切に判断できるAIもあれば、ビッグデータを投入することで本領を発揮するAIもあることでしょう。(pp.43-45) |
この3軸は私の思っている軸とも近いので、しっくりきます。
「強いAI」vs「弱いAI」
「専用AI」vs「汎用AI」
「知識・データの量」
| 全体としては「必要は発明の母」、ニーズの高まりが技術開発を促した側面が大きいように感じます。大きなきっかけはやはり、ビジネス環境がビッグデータ活用に取り組む必要に駆られたことでしょう。対象データの収集とその“お掃除”(data cleaning/cleansing)、データの形式や網羅性の追求、整備が進んだけれど、まだそれをあまり活かせていない。活かすためには、人手でも、何らかの道具を使って分析ができればよいのですが、本当にビッグなデータなので、やはり全部は到底見きれない。目視できた範囲でも、それだけでは経営戦略を左右する「何かを発見しろ!」「アイディアを出せ」といわれても何も出てこない。(p.68) |
「データの量(を格納するストレージの環境)」
X 「それを処理できるテクノロジー」
これがビッグデータとして騒がれ始める根幹のところです。
| 分析に必要な手が足りず、早期の養成も困難ななか、高度な分析力、ノウハウが現場に必要なのを補うには、分析の専門知識を備えたタイプのAIや、規則性を見つけるための大量の計算処理をこなせるAIが必要です。そして、テキストや画像から何が出てくるかわからないなか、もっと柔軟に(従来は人間にしかできなかったような柔軟さで)、何か「発見」するために、「認識」「理解」「解釈」「推論」などがある程度遂行できるAIが必要なのではないでしょうか。ビッグデータ活用、事実データに基づく業務改善や経営判断のトータル・プロセスが機能するためには、このようにAIの支援が必須になってくる、といっても過言ではないでしょう。(p.71) |
まさにビッグデータについてサクサクと処理をこなしていくためには、AIがというわけではないでしょうが、単純にデータを情報に変える機能は必要不可欠となり、そのあたりについての分析の骨格は人間がつくることになると思いますけどね。
| データの選別や、ディープラーニングにトレーニングを施すノウハウという上位置に競争の焦点が移ってくると、オープンソースで商用フリーで提供される解析エンジン自体の価値よりも、その使いこなしのほうに価値が移ってきます。あるいはデータそのものの価値です。それは、生データを購買させる、という意味ではありません。AIにトレーニング(「学習」よりも「調教」に近いイメージです)を施す一時的な利用さえあれば、所有し続けるのは必須ではないのですから。(pp.72-73) |
競争の焦点は、「モデルの質」ということでしょうか。ビッグデータはモデル作成のために一時的に利用すればよいということでしょうか。
| 「人工知能は当面どうやって導入したらよいのだ?」という疑問が湧いてくると思います。その回答は、既存の仕事の流れ、やり方、業務フローを見直し、いったんバラバラに分解(アンバンドル=unbundle)して、次に、AIを取り入れて再構築(リバンドル=rebundle)する、というものになります。すなわち、現時点でAIが担当可能なタスクの中で、効果的なもの、費用対効果の高いもの、従来にない高い性能(精度、速度、品質、品質のバラつきの少なさ等々)のものを、個々のタスクについてAIで置き換えること、また、業務全体のトータルのプロセスと結果について評価、見積もりし、改善効果を確認しつつ導入することになるでしょう。(p.77) |
| 人間の情報認知能力や表現能力、発信能力は突然進化し、大容量化したりできません。このため、やはり、情報量や質を受け手や、発信者である人間の処理容量、様態に合わせて変換するAI的なソフトウェアが必要となってきます。人間がおおまなか指示をしたものをブレークダウンし、欠落情報を適宜補って「よきに計らって」情報収集や問題解決の実務を代行する代理人AIを作るなら、それは「エージェント」と呼ばれます。(p.81) |
| 「なぜ組織や業務フローが、AIなんかを取り入れてまで変わらねばならないのだ?」という疑問が湧いてきます。その大きな要因として、ソーシャルメディアや企業ウェブ、ウェブ広告メディアの浸透により、消費者がサービス提供を企業に対し、リアルタイムに反応してくれることを当然のごとく望むようになったことがあげられます。消費者視点がリアルタイム化すれば、それに対応して、そして、サービスの生産、提供に必要な素材を調達するB2B取引、企業間連携のSCMもリアルタイム化に対応する必要が生じます。(p.82) |
| リアルタイム化を象徴するのが、製造業ビジネスが、いわゆる「モノからサービスの生産・供給へ」と、意識的に業態を変化させている流れです。有名な一例は、電動ドリルの製造販売会社が、自身を再定義して、「われわれはドリルというモノを製造・販売しているのではない。お客様の現場で、穴を開けたい対象物に必要なタイミングで必要な数の穴が必要なコスト以下で開く、というサービスを販売しているのだ」というものです。「サービス化したからって何がどう変わるのか?」という問いには、次のような根本的な違いが生じること、さらに派生して、品質管理から評価のされ方まで、何から何までモノの提供と変わってくることを指摘できます。(p.86) |
これまでは、バリューチェーンのなかでの次のプロセスだけを見ていればよかったですが、これからは常に最終到達地点を意識してビジネスを組み立てていかなければならない。
| 従来コモディティ―と見做されるもの商品で、低価格圧力にあえいでいた商品を販売する事業で苦しんでいたなら、なんらかのサービス事業として衣替えすべきではないかという示唆が得られます。サービス化してブランドイメージを上げ、コスト増を抑えることができれば、利益率を大いに上げられるだろう、という一般論です。人件費の増大を抑えつつ、個別化(パーソナライズ)、カスタマイズして魅力的なサービスをリアルタイムで提供するには、やはり、人の代わりに、安く大量に複製して使えるAIに期待がかかるといえるでしょう。(pp.87-88) |
ちなみに、サービスの特性は以下の通りとなります。(p.86)
“サービス”という商品の基本特性
―その場で(最終)生産され、消費される(リアルタイム性)
・生産行為と消費行為を分離できない
・“触れない”、“目に見えない”ことが多い
・“ストック(在庫)が効かない”、“運搬できない”
・ビジネスプロセス自体が商品
・業務知識=企業ナレッジマネジメントが“製造ライン”
・カスタマイズ性に富む
ある時点のAIでできることがプロセス・チェーンの中の1ファンクションを丸ごと担えないならば、プロセスの表現をさらに細密化し、AIでできることを切り出すことになります。あるいは運用で、常識を不十分にしかもてないAIに対して、もう少し顧客に歩み寄ってもらうなりして、受け取る情報の曖昧さを除去して、その時点のAIにバトンタッチできるようにしても良いでしょう。いずれにせよ、その置き換えの実現に際しては次の検討が必要です。
従来、人が担ってきたサービスの一部をAIが置換するときに、その貢献度、プロセス全体での効率化、スピードアップ、コスト削減効果を数字にするのは容易ではないでしょう。ひいては、安易にAIの効果の数字やAI市場の数字を見積もることも自戒すべきと思われます。(pp.90-91) |
そして、例えば、ホテル宿泊客受付で生かされ始めています。
| 昨今、宿泊や旅客運輸サービスでは一物多価が当たり前。そこでは、「イールドマネジメント」というソフトウェアが、なるべく高レートの上客で空室・空席を埋めるべく大活躍します。過去の履歴データ、顧客プロフィールをもとに確率計算を行い、当該レートで目下の客を受け付けてしまった後でもっとレートがよく、長く泊まってくれる客が期限までに現われる確率が十分低い、となったときにその客を受け付けます。・・・このイールドマネジメントというソフトウェアに、もっと投機的な判断や最終判断まで任せるようにしたり、目の前の客の表情を読ませたり、顔認証で本当にリピート客かをチェックしたり、という機能を付加していくと、次第に、AIと呼ばれるのにふさわしい存在になっていくことでしょう。(pp.92-93) |
イールドマネジメント:イールドマネジメントとは、ホテルや航空会社で単位あたりの収益を最大化する販売戦略。欧米でいちはやく導入され、日本には90年代後半に浸透した。ホテルのOCC(客室稼働率)や航空会社のロードファクターを上げるためだけに客室や運賃の割引率を大きくすれば、イールド(収益)は必然的に低下する。一方で、乏しい需要に対し割引を少なくすると売れ残ることがある。そこで、イールドを最大限確保するために、過去の販売データや需要動向を細かく見ながら販売単価や提供客室・座席数を管理するようになってきた。航空会社の国内運賃がその典型で、過去の販売データなどを参考に各種運賃や運賃ごとの座席数が設定されている。
(JTB総合研究所:URL)
| 人工知能、特に、今回の第3次AIブームの立役者であるディープラーニングは、ビッグデータに支えられて性能を発揮し、また、人手では分析しきれないビッグデータの解析には、道具としてAIを使うしかない、という相互依存の関係があります。IoTでは、人口よりはるかに多いくらいの対象物センサーを取り付け、それが常時大量のデータを吐き出すようになるので、そのビッグデータを人手で解析するのは最初から不可能。AIが必須となってまいります。(p.94) |
さらにもう一つの必要十分条件として、テクノロジーの発展なくしては語ることができません。安価で大量に、さらに高速にアクセスできるハードディスクのテクノロジーがあってこそビッグデータを扱うことができるわけですし、そこから抽出されたデータに対して複雑で高度なアルゴリズムを実行できるのも処理速度の超高速なCPUなくしては成り立たないものです。これらが2010年以降バランスよく結びついたのが今回のAIということだと考えます。
またデータの発生というところでいうと、RFID(Radio Frequency IDenitfier)の発展もその一つです。
| モノに密着し、埋め込まれたRFIDや、温度「体温)、湿度、振動(脈拍など)などのセンサーに加えて、IoTの基本的な構成要素には次のものがあります。まず、「1.モノ」です。人間が介在しないIoTではありますが、それは、この「1.モノ」と、「2.センサ」が合体し端末の存在を意識し、それと向き合わない、という意味です。ですので、「1.モノ」が人体、手首などの人体の一部であってもIoT端末の構成要素となり得ます。人間の体内を通る薬の錠剤や人工臓器がRFID付のIoTになることも可能でしょう。微小電力でいくつかの専門機能に限ってひたすらデータを送受信するだけとはいえ、そこには「3.プロセッサ」も必要です。そしてもちろん、「4.通信機能」」が必須です。「4.通信機能」は通常、半径数メートル以下の中継器や、近寄ってきた人の持つスマートデバイスなどまで短距離、一つ一つのIoTデバイスは少量のデータを送ります。今後はスマートフォンが、一昔前のスーパーコンピュータ並みの強力なプロセッサによる処理能力を活かして、クラウド上の「5.データ処理」を仲介するケースが多くなるでしょう。(pp.96-97) |
発信機 → (受信 × 最適提案 × 発信) → 受信機
この図式を成り立たせるうえでは、発信機と受信機がひとつのポイントですが、個々人がスマートフォンを携帯するということでこれが成り立つようになりました。あとは、最適提案をどうするかと、この上の図式を成り立たせるビジネスモデルをどう作っていくかです。次の例が挙げられています。
・ドイツのERPベンダー:生ビール消費のリアルタイム監視
・フィリップスのLED電球「Hue」
・JR東日本:山手線E231系の床に備わった重量センサー&気温センサー
さて、ここから第4章、「データ解析がもたらす企業経営の変化:“アナリティックス”が支える“事実”に基づく経営」です。ここは私の主戦場でもありますし、しっかり咀嚼したいと思います。
| 英語のData Analytics(DA)の定義は、Tech Targetのサイトによれば、
Data analytics (DA) is the science of examining raw data with the purpose of drawing conclusions about that information. 「データ・アナリティックスは、対象とする情報についてのなんらかの結論をいくつか引き出す目的で生データを検査・分析する科学的手法のこと」となっています。似て非なるデータマイニングが、パターンやデータ間の相関関係を発見することを目的としているのに対し、アナリティックスのほうは、そこから推論を行い、意思決定を行うことを目的としています。単純なパターン認識を超えて、推論という、よりAIらしい言葉が出てきました。(p.105) |
Tech Targetの説明には、ちょうど私の一番の関心分野でもあるところが、“Modern data analytics”と書かれていました。
Modern data analytics often use information dashboards supported by real-time data streams. So-called real-time analytics involves dynamic analysis and reporting, based on data entered into a system less than one minute before the actual time of use.
これは、高速のデータベースと次世代BIツールとの結びつきが実現するところのものです。企業が消費者や取引先にデータ分析結果をフィードするところもあるし、企業内でのアクションプランに向けてのデータの円滑な利活用という部分もあります。
ちなみに次世代BIツールはこちら(資料①、資料②)に詳しく紹介されています。
| データが安く大量に溢れるビッグデータ時代であればこそ、「何をデータ化しないか」を考えるのがポイントとなるかもしれません。・・・当時は、まだ高価だったITインフラ、システム開発費用を節減して無節操なコスト増を抑えるのが主目的だったでしょう。ビッグデータ時代に、「何をデータ化しないか」、あるいは、主たる解析対象から外すかの判断は、アナリティックスにおいて、間違った推論を行い、誤った結論(ただの偶然生じた数字の相関に意味づけしてしまうなど)を導かないためにこそ重要と思われます。(p.108) |
事前にデータのごみを取っておくということです。CRISP-DMというデータマイニング・プロセスがありますが、そこでも最初のフェーズがデータのクレンジングです。あらかじめゴミを除去しておくことでクレンジングの手間も省けますので、データベースの設計、また分析データセットの作成の段階であらけじめゴミを除去するように心がけておくことで、あとあとの効率化が図れます。
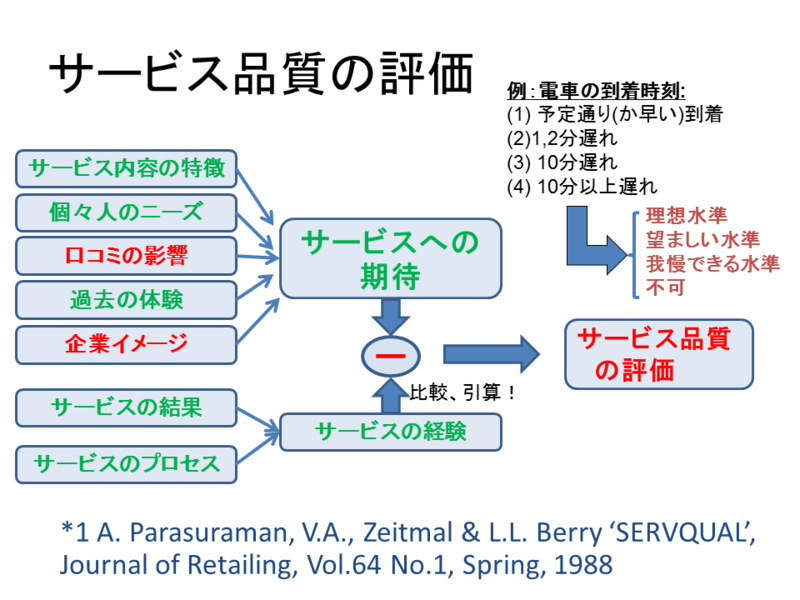
| IT関係者のあいだで「サービス科学」が語られ始めたのは1990年代末くらいからですが、実は、海外の「小売り学会」の学術誌 Journal of Retailing や、そこからまとめられた学術書には、すでに70年代、80年代から、今日でも通用し、重要な知見を与えてくれる内容があります。マーケティング施策自体もサービスに他なりませんので、その評価にあたっては、モノ商品と違った様々なサービスに共通する「評価』原理を考慮する必要があります。(p.122) |
(引用:http://blogs.itmedia.co.jp/nomuran/2011/08/facebook-8608.html)
その最大の特徴は、「サービス品質の評価SERVQUAL法」に示すように、事前の期待値、内容が実際のサービス体験を上回ったか下回ったかで、大きくレバレッジの利いた評価がなされることにあります。サービスへの事前期待は、下記のような要因によって形成されます。
そして、今回のサービスの実体験の良否の度合いは、
|
SERVQUALは有名なサービスの評価法です。これと人工知能との組み合わせ、おもしろいです。
| サービスの実体験の評価にしても、結果に満足したかだけでなく、プロセスにも満足できたか、別の設問なり、自由回答にてコメントを集めることが大事でしょう。この自由回答を先述のAI型の分析ソフトウェアで分析すれば、なぜそのような評価となったかについて、事前期待を形成する複数の軸や、結果とプロセスを区別して浮き彫りにすることができるでしょう。原因の定量分析、定性分析を踏まえることで、マーケティング施策を含む、具体的なサービス改善の施策を描き出せるようになります。(p.124) |
サービスにもいろいろな分類があるようで、クリストファー・ラブロックが行った分類が引用されています。
| サービスの対象 | |||
| 人 | 所有物 | ||
| サービス活動が目に見え触れるか | 有 形 の 働 き か け |
“人の身体へのサービス” ●交通機関 ●医療 ●宿泊 ●飲食 ●エステ ●スポーツ ●理美容 ●葬祭 |
“所有物へのサービス” ●モノの輸送 ●修理・保全 ●倉庫・貯蔵 ●清掃 ●衣服のクリーニング ●給油 ●廃棄物処理 ●庭園管理 |
| 無 形 の 働 き か け |
“人の心、脳へのサービス” ●広告・宣伝 ●エンターテインメント ●放送 ●教育 ●コンサルティング ●カウンセリング ●コンサート ●宗教 |
“無形資産へのサービス” ●会計 ●銀行業務 ●情報処理 ●保険業務 ●法律サービス ●プログラミング ●調査 ●投資顧問 |
|
[amazonjs asin=”4561651276″ locale=”JP” title=”サービス・マーケティング原理”]
サービスの事前―事後の期待変容をUPさせるための方法の探索・・・さすがにそんなことは今のAIでも無理です。過去に打った手しか打てない。誰も思いつかないような手は、人間にしかできない・・・・それを覆す日は来るでしょうか・・・・。
| データ・サイエンティストに求められるスキルとは、どのようなものなのだろうか。ダベンポート博士によると、それは大きく分けると、技術、ビジネス、分析、そして人間関係の4つだという。技術は、コンピュータを使いこなす能力を指す。ビッグデータを扱うため、大容量データを効率的に処理するシステム環境の構築から、データを処理するプログラミングまで、相当に高度なスキルが要求される。単にデータを処理するわけではない。ビジネスの現実を知らなければ、新しいことを考える方向性を見誤ってしまう。ビジネスを知り、正しく分析することが要になる。この、ビジネスと分析の能力は、いわゆるビジネスアナリストの役割と似ている部分だろう。最後に人間関係(コミュニケーション能力)を取り上げた視点が面白い。従来型のビジネスアナリスト像を語るとき、人間関係はビジネススキルの範疇にあった。それをわざわざ独立させたのには意味がある。ビジネスアナリストは意思決定者とコミュニケーションできれば問題なかったが、データ・サイエンティストはそれに加えて製品マネージャーや企画幹部、サービス所長、チームメンバー、そして顧客など、幅広い人々と意見を交換する必要があるためだ。これら4つの能力を兼ね備えた人材は、現実にはほとんど存在しない。そこで多くの企業は、データ・サイエンティストのチームを編成する。(pp.133-134) |
ビッグデータを使っていくら機械学習させても、その学習からはこれまでになかった新しい一手が出てくる可能性は非常に低い。それができるのは人間であり、過去データの分析からその一手を導き出し、そして経営陣にその一手の可能性を説明し納得してもらうところまで持っていくことができる・・・・そこまでのスキルをもってこそ、“データ・サイエンティスト”であり、世界一SEXYな職業と言われるゆえんでもあるのだと思います。
「シンギュラリティ」を目指し、超知能の実現を加速しようという動きもあるようです。松田卓也氏によると「来たるべきシンギュラリティと超知能の驚異と脅威」では、様々な「超知能の作り方」が紹介されています。(p.157)
|
| 2016年時点の現実、ディープラーニングが今できること、まだできないことの話に戻ります。CNN(Convolutional Neural Net)と並んで良く用いられているディープラーニングの手法に、RNN(Recurrent Neural Net)再帰型ニューラルネットがあります。RNNは、音声や言語、動画像などの、時間軸上に変化していくデジタルデータを扱うのが得意です。(pp.159-160) |
ディープラーニングは、2012年イメージネットのLarge Scale Image Recognition Challenge という大規模な画像認識精度比較コンテストにおける飛躍的な認識率向上により、注目を浴びました。このブレークスルーをもたらした歴史的な要因は3つ挙げられます。(p.164)
|
| 直観的に説明すると、有為な特徴抽出ができるかどうかは、各種原稿を小さなサムネイル画像にした時、人が見てパッと分かるようなら、ディープラーニングで、それ以上の精度が出せるようになる可能性がある、と大雑把に考えてよさそうです。そのために独創的な新アルゴリズムを考案する必要は必ずしもありません。むしろ、適切なデータセットを選び、積み重ねたノウハウで、質・量ともに適切なトレーニング(調教)を施すほうが精度向上、ひいては実用性に効いてきます。このあたりの評価と、なによりも産業応用上のアイディアを膨大な研究論文の10倍くらい、同じ期間にたくさん出せるようになれば、その国や地域のAI応用は大発展するでしょう。このように、あるAIの進化、応用のステージでは、アルゴリズムより調教用のデータ作り、選別が実用面で重要なので、今後の進化、急激な変化、特徴量抽出手法の早い廃りによらずに、実用精度の向上を早期に達成するのが重要です。(p.168) |
確かに画期的な精度を出すアルゴリズムの開発となると、それだけで一生涯をかけて開発しないといけません。例えばビジネスユースでの案件対応などとなると、データマイニングの場合だと適切なデータセットの作成と適切な変数探しが、そしてAIだと適切なデータセット作りが精度向上への近道でしょう。
| ディープラーニングという計算の仕組み自体は機械学習の一種であり、アイディア次第で様々な応用可能性があります。ディープラーニングには、CNN(畳み込みニューラルネットワーク)や時系列、“文脈”に強いRNN(再帰型ニューラルネットワーク)、LSTM(長短期記憶付きニューラルネットワーク)など多数のバリエーションが続々と出現しており、今後、確実にその応用用途は広がっていくでしょう。(p.173) |
| ディープラーニングによる認識や、自動抽出された特徴に基づく分類だけでは、人間がするような分析、学習、理解、因果関係の推理、発明・発見をこなしているわけではありません。分析、学習、理解、推理、発明・発見、さらに新手法の開発や創作を含む知識創造のためには、知識や、その素材となる概念、そして、概念を表現する強力な道具としての自然言語―英語や日本語などの言葉を操り、意味のやりとりをコンピュータが扱えるようになる必要があります。人間と対話し、コミュニケーションを通じて、より良い問題解決を図るためにも、現在の対話ロボットの「無難な応答」志向をはるかに超えた自然言語を操る能力が必要です。(p.176) |
いわゆるチャットボットはこれに該当するところでしょう。
| 目の前の情報を把握し、その意味、さらには自分にとっての価値を判断するスピード、人間の情報処理能力はインターネット誕生以来、数十年程度の時間で、急に100倍、1000倍にはなりません。生物の進化には、その1000倍、1万倍以上の時間が必要でした(少なくともこれまでは)。そこで、要約(サマライズ)はますます、重要になってきます。アクセス可能な情報量が加速度的以上に増えても、1日の時間は24時間と変わりません。アテンション・エコノミーという経済の考え方が語るように、消費者の可処分所得よりも可処分時間にこそ注目して、B2Cサービス企業が消費者のもっとも貴重な資源である時間を奪い合うようになりました。ですから、やはり、加速度的以上に増える情報から、なんらかのAIアシスタントが、個人の価値観などをある程度写し取り、記憶してくれるパートナーのような仕組みを備えて、目を通すべき情報を選別、ランキングした上で情報量を大幅に圧縮。そして、数分の一、数十分の一の時間で全体の要点が把握できるよう、人間が理解しやすく、すばやく価値判断できるような、優れた要約(サマライズ)を行ってくれることが期待されます。(pp.190-191) |
限られた可処分時間のなかでどれだけタイムシェアできるか・・・まさに時間の奪い合いです。
| 「企業はいま、自社の様々な情報やサービスへのアクセスを、APIを通じてオープン化しようとしている。この流れに乗り遅れれば、あなたの企業はインターネットにアクセスできないコンピューターのような無用の長物になってしまうだろう」。API提供の老舗となった巨大インターネット・サーバ運営企業はもちろん、蒸すのベンチャー企業に至るまで、商用ベースでAPIを地教師、APIが相互に機能提供し、通信することで協同で問題解決を行い、業務フローを回し、売上をシェアできるようになりました。これこそ、21世紀のエージェント志向ではないでしょうか。(p.201) |
確かに、一種のエージェントですね。そんなふうに考えるのは面白い発想です。
| 前回のAIブームからの30年間の諸分野の進展と最近の状況から考えると、2015年の時点で、このような能力を備えた自律的な人工知能が誕生している可能性は必ずしも高くないように思えます。それは、自動で知識獲得ができるようになるために必要な知識量が数億程度では何桁も足りないことが分かってきているからです。それ以上の知識量を人手で構築するのは事実上不可能ですので、この点でAIは壁に突き当たっている感があります。(p.211) |
「学習」と「創造」の違いといった感じでしょうか。「学習」力はまだまだ上がっていくと思いますが、「創造」となるとまさに計算量にしても次元がいくつも加わることになるでしょうからね。
| リアルタイムで即断が求められるシーンは、デイ・トレーダー、自動車・航空機などの運転・操縦などの象徴的用途はもちろん、様々な業務の現場、そして、経営者にとっては日常シーンと重なります。このような決断シーンでは、究極の最適解などは神のみぞ知るものであるか、あるいは存在しないかもしれません。そうであるなら、根拠を理詰めで理解できなくとも、過去の事例、経験則の組み合わせから一定の妥当性をもつと考えられる機械学習の出した結論から選択することには十分な合理性があります。(pp.215-216) |
ここからは「第Ⅱ部 人工知能が支える10年後のビジネス」に入ります。これからホットになるビジネス領域、つかみ取りたいと思います。
これまでに記した3軸「強い vs 弱い」「専用 vs 汎用」「利用する知識やデータが大規模 vs 小規模」とは異なるAIの分類を試みます。こんどはAIを用いたサービス、あるいはAI的なサービスの分類です。
1.は人間しかできない、とその時点で思われていたこと、写真や動画を見て何が映っているか、ものの名前や人名を言い当てたり、鳴き声が何の動物であるか言い当てるなど、最近ディープラーニングで可能になった多くのことが含まれます。高度専門知識を提供する医療、法務、会計などでは、コンピュータがもともと得意だったこと以外で、画像や文章の意味を判断するなどで、一般人や一部専門家の能力を凌駕する事例が出てきました。秘書サービス、接客サービス、介護や料理をはじめとする家事代行サービスなどは、時にロボットという身体も備えて、人間を支援する多彩なサービスがあります。 2.としては、以前の人工知能ブームでは、論理推敲マシンを使ったエキスパートシステム、それ以前に、LISPやPrologといった人工知能プログラミング言語を使ったシステムだからAIである、といった少々粗雑な分類が該当しました。ここでは、ディープラーニングを用いた問題解決でありながら、1.にも3.にもまったく該当しない例として、「アッパコンバータ」を挙げてみたい。・・・ディープラーニングに学習させることで、高解像度の元の絵が「推定」され、合成される、というわけです。まったく知的な感じも人間味もない機能で、ハードウェア、LSIチップが機械的に処理しているのだろう、と思う人が多いですが、こんなところにも最近のAIの手法(アルゴリズム)が応用されているのは興味深いと思います。多彩なAIの応用法があるのであり、基本的には道具にすぎないのだ、という認識を得るのにも好適です。 3.に該当する「知的な感じがする」のは、コンサルティング、カウンセリング、法律サービスのように、”人の心、脳へのサービス”、”無形資産へのサービス”などの無形の働きかけに該当するものが多いでしょう。”人の心、脳へのサービス”を実現するには、人との対話機能が、インターフェースとして必要となります。(pp.259-262) |
従来存在しなかった、AIを活かした新サービス、新製品は、次の要件が満たされて初めて出現します。(p.264)
|
| AIは、ビッグデータを解析・検索させてやれば、類似のものがないか、膨大な候補からたちどころに探してくれます。これを、アイディアを具現化した素材として引用し、著作権に注意しつつ変換、変形して作品の一部の参考とするもよし、逆に、斬新なデザイン、クリエイティブ作品を生み出すために模倣を回避すべき対象とするもよいでしょう。AIの新サービスの開発というより、AIの助けを借りて新サービスの構想を練り開発する、というものです。これは、人とAIの協調による創造的な問題解決の一種と位置付けられます。(p.273) |
| マーケティング自動化の思想的なルーツ(起源)は次の2つがあります。 ●インバウンド・マーケティング(Inbound Marketing) ●1 to 1 マーケティング(One to one Marketing)撒き餌のように相手を選ばずマス広告を打って、購入した名簿の記載順に片っ端からアポ取り電話をかけ、訪問セールスへとつなげる従来型の、伝統的なマーケティングのことをアウトバウンド・マーケティング(Outbound Marketing)といいます。これに対し、インバウンド・マーケティングは、まったくの逆方向。すなわち、お客様にウェブサイトやソーシャルメディアで自社商品・サービスに気づいてもらい、微かな興味でコンタクトしてくれたお客様に的確な内容、適切な粒度(詳細度)の情報を提供して興味を深めていただく、そして先方からECサイトや店舗に来訪してもらい、その後はリピーターになってもらう、というマーケティング戦略手法です。最初のコンタクトを通過した顧客候補をマーケティングでは「リード(lead)」と呼びます。前記のように、次第に顧客候補の興味、関心、商品・サービスへの好感度を高め、購買層、リピーターへとなってもらうようにするプロセスをリードの育成という意味で、リード・ナーチャリング(lead nurturing)と呼びます。(pp/340-341) |
| 人工知能がインバウンド・マーケティングにおいて果たす大きな役割は、このプロセスのより上流の段階から、個別的な対応を可能とし、リード・ナーチャリングの効果を向上させられる点にあると考えられます。疲れを知らずに、大量の個別化、マス・カスタマイゼーションを低コスト、短時間でできるのが人工知能だからです。(p.342) |
| 1to1マーケティングの目的は、「新規顧客の開拓は(補充以外は)行わず、既存顧客層の忠誠心を高め、その顧客が死ぬまでの障害購買金額(LTV=Life Time Value)を最大化すること」です。(p.343) |
1to1マーケティングに基づくE-ビジネスのための技術要件(p.344)
| 1to1以前 | 初級 | 中級 | 上級 | |
| Identify | 個客を認識せず | ・一部VIP客を認識 ・インセンティブ実行 ・プライバシ配慮 |
・回帰客を認識 | ・詳細なプロファイリングを活用 |
| Differentiate | 好みを無視した画一仕様 | ・ニーズで再編 ・顧客が選べるクイック・ナビを提供 |
・オン/オフライン間データ統合 | ・顧客を/のために記憶 ・協調フィルタ提供 |
| Interact | 顧客と接して控える最小限の情報の管理 | ・効果的なオンラインのe-service | ・微小負担の繰り返しでgive&take | ・個人情報管理代行 ・個人別プッシュ発信 |
| Customize | 同一内容を全顧客に発信 | ・顧客毎にカスタマイズした共有体験の提供 | ・パートナーベンダーと統合 ・個人情報創製 ・WishLists |
・推奨 ・自動補完 ・製品構成作業をWebで提供 |
(参考:1to1マーケティングに基づくE ? ビジネスのための技術要件)
| アシモフの「ロボット工学三原則」(p.448) 第一条 ロボットは人間に危害を加えてはならない。また、その危険を看過することによって、人間に危害を及ぼしてはならない。 第二条 ロボットは人間にあたえられた命令に服従しなければならない。ただし、与えられた命令が、第一条に反する場合は、この限りでない。 第三条 ロボットは、前掲第一条および第二条に反するおそれのないかぎり、自己をまもらなければならない。 |
| 「なぜ?」を考えられる人であれば、よほど完全に機械の部品として仕事させられているような職業以外では、どんな業界、職種、地位であっても生き残れる。そして、純粋に「なぜ?」を発しつづけられるように、子供のように素直な好奇心や健全な競争意識、上から与えられた現状に甘んじずに、より良い環境や成果物を作り上げようという、人間らしいモチベーションを自ら育成することがAIより優位に立つうえで大事でしょう。(p.469) |
最後は駆け足での紹介になってしまいましたが、元々私の方での理解しているAIとほぼ同じ解釈でしたので、確認ができてよかったです。とはいうものの、なかなか言葉にすることはできてなかったので、多くを引用させていただきました。
あらためて、勉強になりました。
[amazonjs asin=”4532320631″ locale=”JP” title=”人工知能が変える仕事の未来”]